Lorenzo Lazzari

Tech & AI enthusiast | Statistician by training | Experienced Python developer
![]() LinkedIn
LinkedIn
![]() CV/Resumé
CV/Resumé
![]() Github
Github
![]() Kaggle
Kaggle

• Case Study: Leveraging Large Language Models in a Hybrid Search System for Improved CSR Information Retrieval

Context = Industry Research Poster Presentation at CLIN 2024 (The 34th Meeting of Computational Linguistics in The Netherlands, Leiden)
Keywords =
Information RetrievalLLMsFine-tuningNLPOpenAIMetaPoster that presesents an Information Retrieval (IR) solution designed to assist sustainability analysts in efficiently retrieving CSR-related information from large multilingual company documents. The system combines a scalable traditional search engine with a Large Language Model (LLM) reranking and filtering step to improve precision. Two approaches were explored:
- Unsupervised Prompt Engineering using GPT-4 for reranking and filtering.
- Fine-tuning a smaller LLaMA3-8B model, leveraging analyst feedback for continuous learning and improving relevance scoring.
The results demonstrate that fine-tuned, task-specific LLMs can achieve comparable performance to much larger, resource-intensive models. The full details and methodology are available in the CLIN 2024 poster.

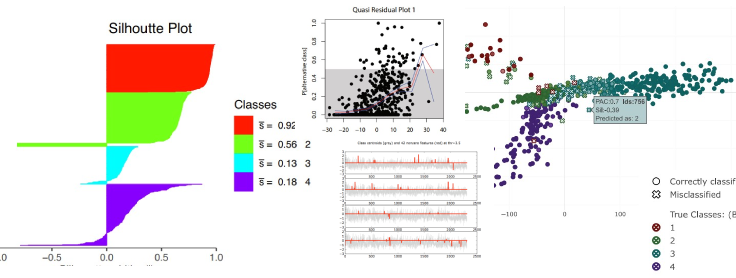
• Graphical displays to better understand ML classifiers results




Context = Master Research Thesis
Keywords =
ML classifiersDiagnosticVisualizations ToolsR Package DevelopmentSilhouttesHigh Dimensional DataGenomicsRNA-seq pipelinesResearchMDSplotly
In my Statistics master’s degree thesis, I explored novel machine learning (ML) visualization tools like Silhouettes, Class Maps, and Quasi-residual plots, accessible via the R “classmap” package. A new tool, MDScolorscale, was introduced to further enhance these visualization methods. This work also developed a versatile function that allows the use of these graphical tools for almost any ML classifier, extending their applicability. An extension package named “classmapExt” was released. Practical application of these methods was illustrated by using them to diagnose gene-expression-based cancer classifications with the Nearest Shrunken Centroid Classifier and the XGBoost classifier
• Spain Data Job Dashboard

Context = Personal project
Keywords =
ScrapingNoSQL DatabaseAzure CosmosDBAzure FunctionsPowerBIEspañol
This project aims to create a publicly accessible Power BI dashboard that displays real-time data about job offers and salaries in the data field, specifically in Spain. The dashboard provides historical records of the data and analyzes four main job categories: Data Engineer, Data Scientist, Data Analyst, and Business Analyst. This is achieved by deploying an Azure Function to scrape data from glassdoor.es, the Spanish version of Glassdoor, using Beautiful Soup, which is triggered daily by a timer. The data is then uploaded to an Azure Cosmos DB NoSQL database and accessed by Power BI to generate visualizations for the dashboard. The dashboard refreshes daily to reflect the new data loaded into the database. The live dashboard is available here

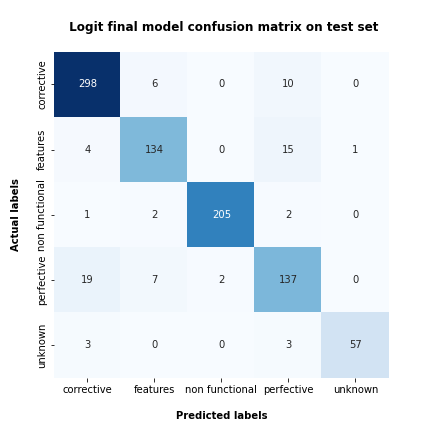
• Commit Classification using NLP
Context = University Project
Keywords =
Supervised LearningNLPText Preprocessing (Stem, Lem)Text Vectorization (n-gram,skip-gram)Logistic RegressionFasttext by Facebook

In this project, I aimed to replicate the work done in this paper. The project started with a 5-class labeled dataset of commit messages, and classical NLP techniques such as data cleaning and feature extraction were used to preprocess the data. Then, several baseline classification models were fitted and evaluated. One of the models was chosen and fine-tuned using RepeatedKFold validation. Finally, the chosen model (a logistic regression) was evaluated on the test set to measure its performance.